01 — Automated scale ratings
From mental health scale audio to scores.
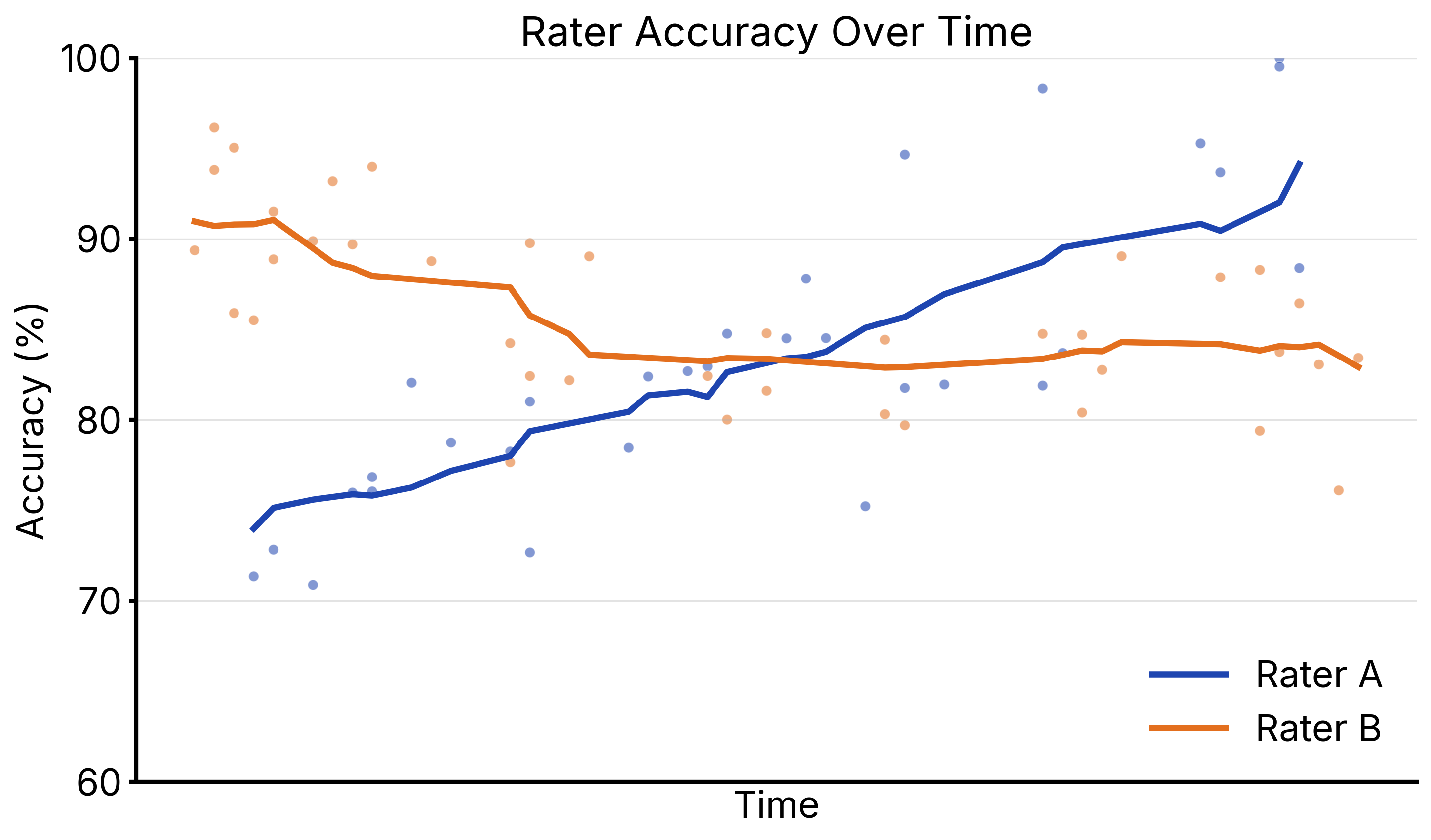
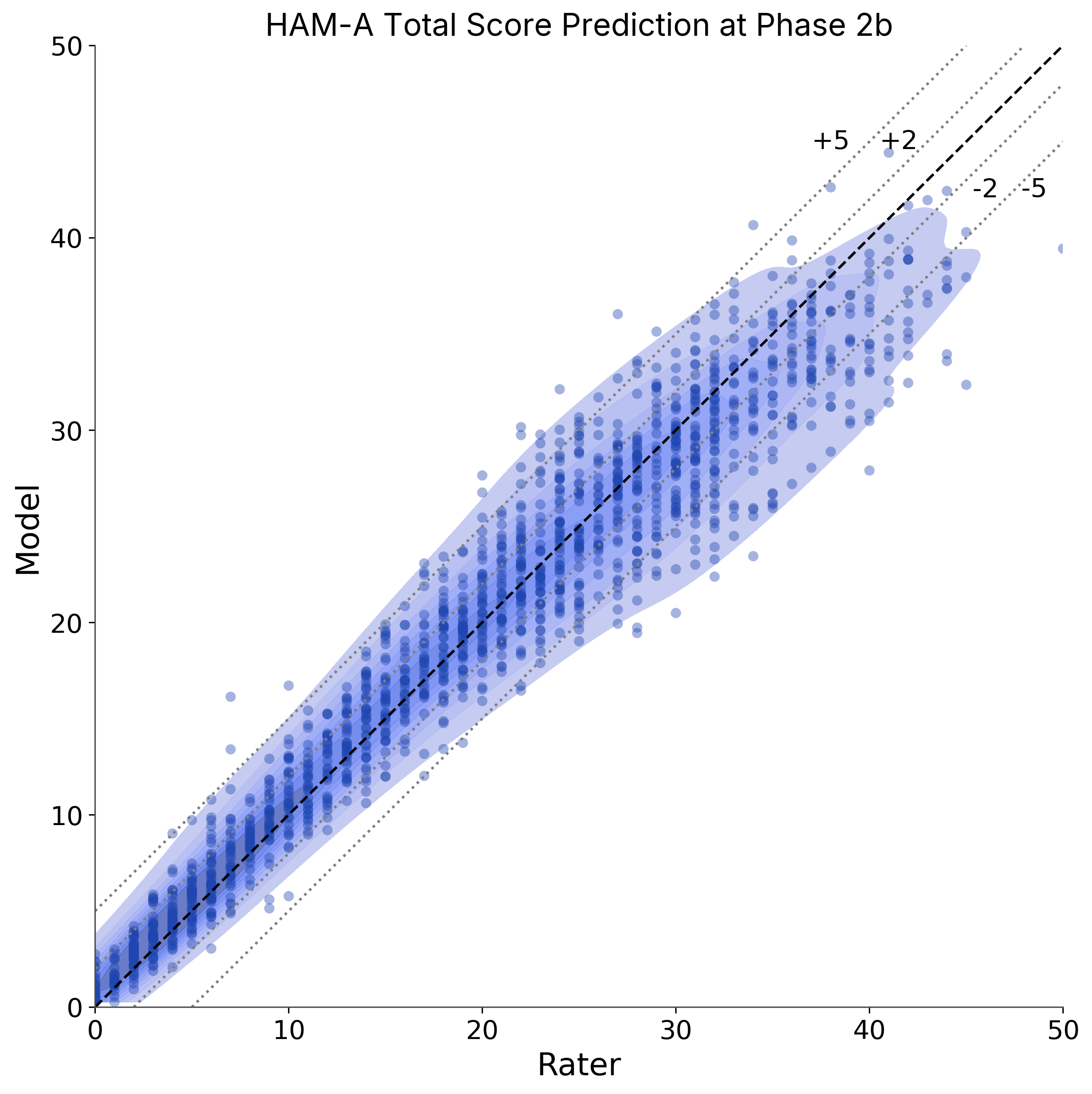
Central raters run their usual questionnaire. Mira ingests the audio locally and outputs item-level scale scores that track closely with trained raters.
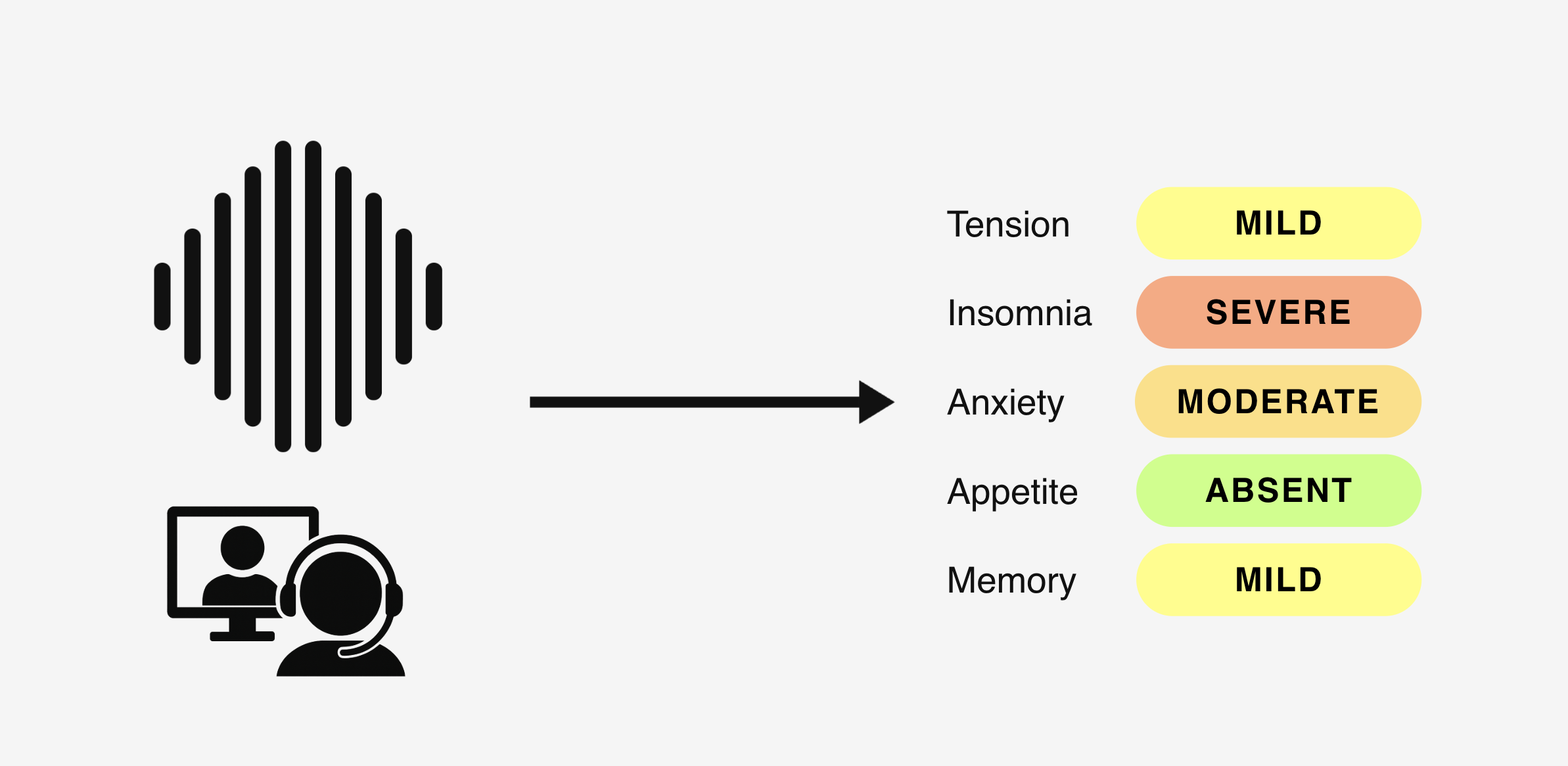
Interview waveform flowing into a Mira engine and bar chart of scale ratings.